Sharding Considerations
MongoDB Sharding isn't just an effective way to scale out your database to hold more data and support higher transactional throughput. Sharding also helps you scale out your analytical workloads, potentially enabling aggregations to complete far quicker. Depending on the nature of your aggregation and some adherence to best practices, the cluster may execute parts of the aggregation in parallel over multiple shards for faster completion.
There is no difference between a replica set and a sharded cluster regarding the functional capabilities of the aggregations you build, except for a minimal set of constraints. This chapter's Sharded Aggregation Constraints section outlines these constraints. When it comes to optimising your aggregations, in most cases, there will be little to no difference in the structure of a pipeline when refactoring for performance on a sharded cluster compared to a simple replica set. You should always adhere to the advice outlined in the chapter Pipeline Performance Considerations. The aggregation runtime takes care of distributing the appropriate parts of your pipeline to each shard that holds the required data. The runtime then transparently coalesces the results from these shards in the most optimal way possible. Nevertheless, it is worth understanding how the aggregation engine distributes work and applies its sharded optimisations in case you ever suffer a performance problem and need to dig deeper into why.
Brief Summary Of Sharded Clusters
In a sharded cluster, you partition a collection of data across multiple shards, where each shard runs on a separate set of host machines. You control how the system distributes the data by defining a shard key rule. Based on the shard key of each document, the system groups subsets of documents together into "chunks", where a range of shard key values identifies each chunk. The cluster balances these chunks across its shards.
In addition to holding sharded collections in a database, you may also be storing unsharded collections in the same database. All of a database's unsharded collections live on one specific shard in the cluster, designated as the "primary shard" for the database (not to be confused with a replica set's "primary replica"). The diagram below shows the relationship between a database's collections and the shards in the cluster.
UPDATE October 2024: From MongoDB 8.0 onwards, you can move an unsharded collection from the designated primary shard to another shard. Consequently, if you are running MongoDB version 8.0 or greater, wherever you see a reference to "Primary Shard" in this chapter, interpret this as meaning "the shard holding the unsharded collection".
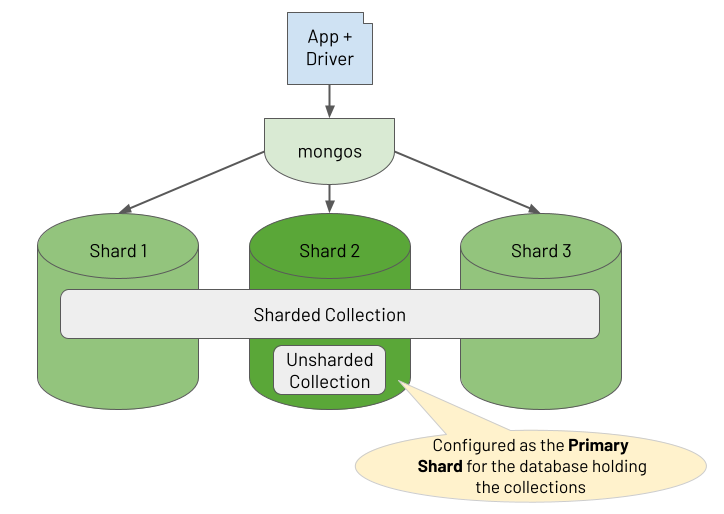
One or more deployed mongos processes act as a reverse proxy, routing read and write operations from the client application to the appropriate shards. For document write operations (i.e. create, update, delete), a mongos router knows which shard the document lives on and routes the operation to that specific shard. For read operations, if the query includes the shard key, the mongos knows which shards hold the required documents to route the query to (called "targeting"). If the query does not include the shard key, it sends the query to all shards using a "scatter/gather" pattern (called "broadcasting"). These are the rules for sharded reads and writes, but the approach for sharded aggregations requires a deeper explanation. Consequently, the rest of this chapter outlines how a sharded cluster handles the routing and execution of aggregations.
Sharded Aggregation Constraints
Some of MongoDB's stages only partly support sharded aggregations depending on which version of MongoDB you are running. These stages all happen to reference a second collection in addition to the pipeline's source input collection. In each case, the pipeline can use a sharded collection as its source, but the second collection referenced must be unsharded (for earlier MongoDB versions, at least). The affected stages and versions are:
-
$lookup. In MongoDB versions prior to 5.1, the other referenced collection to join with must be unsharded. -
$graphLookup. In MongoDB versions prior to 5.1, the other referenced collection to recursively traverse must be unsharded. -
$out. In all MongoDB versions, the other referenced collection used as the destination of the aggregation's output must be unsharded. However, you can use a$mergestage instead to output the aggregation result to a sharded collection.
Where Does A Sharded Aggregation Run?
Sharded clusters provide the opportunity to reduce the response times of aggregations. For example, there may be an unsharded collection containing billions of documents where it takes 60 seconds for an aggregation pipeline to process all this data. Instead, suppose a cluster of four shards is hosting this same collection of evenly balanced data. Depending on the nature of the aggregation, it may be possible for the cluster to execute the aggregation's pipeline concurrently on each shard. Consequently, the same aggregation's total data processing time may be closer to 15 seconds. However, this won't always be the case because certain types of pipelines will demand combining substantial amounts of data from multiple shards for further processing. The aggregation's response time could go in the opposite direction in such circumstances, completing in far longer than 60 seconds due to the significant network transfer and marshalling overhead.
Pipeline Splitting At Runtime
A sharded cluster will attempt to execute as many of a pipeline's stages as possible, in parallel, on each shard containing the required data. However, certain types of stages must operate on all the data in one place. Specifically, these are the sorting and grouping stages, collectively referred to as the "blocking stages" (described in the chapter Pipeline Performance Considerations). Upon the first occurrence of a blocking stage in the pipeline, the aggregation engine will split the pipeline into two parts at the point where the blocking stage occurs. The Aggregation Framework refers to the first section of the divided pipeline as the "Shards Part", which can run concurrently on multiple shards. The remaining portion of the split pipeline is called the "Merger Part", which executes in one location. The following illustration shows how this pipeline division occurs.
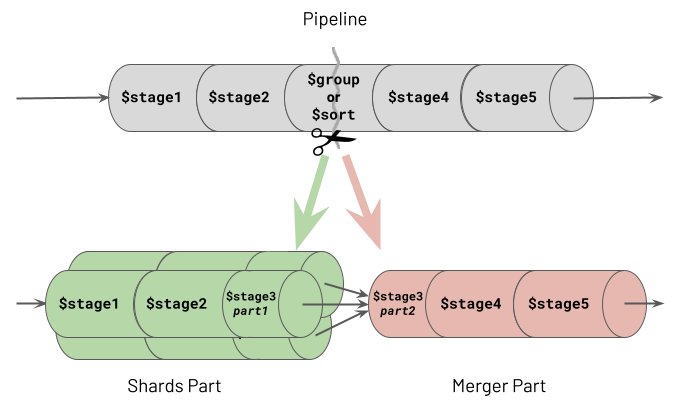
One of the two stages which causes a split, shown as stage 3, is a $group stage. The same behaviour actually occurs with all grouping stages, specifically $bucket, $bucketAuto, $count and $sortByCount. Therefore any mention of the $group stage in this chapter is synonymous with all of these grouping stages.
You can see two examples of aggregation pipeline splitting in action in the MongoDB Shell screenshots displayed below, showing each pipeline and its explain plan. The cluster contains four shards ("s0", "s1", "s2" and "s3") which hold the distributed collection. The two example aggregations perform the following actions respectively:
-
Sharded sort, matching on shard key values and limiting the number of results
-
Sharded group, matching on non-shard key values with
allowDiskUse:trueand showing the total number of records per group
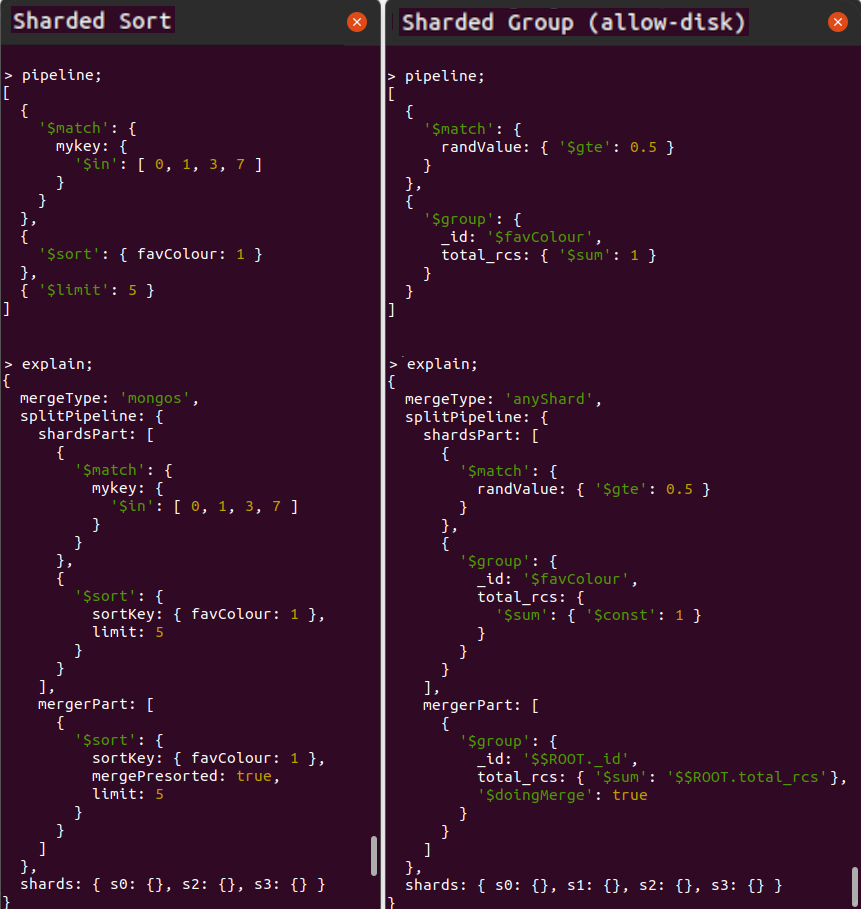
You can observe some interesting behaviours from these two explain plans:
-
Shards Part Of Pipeline Running In Parallel. In both cases, the pipeline's
shardsPartexecutes on multiple shards, as indicated in the shards array field at the base of the explain plan. In the first example, the aggregation runtime targets only three shards. However, in the second example, the runtime must broadcast the pipeline'sshardsPartto run on all shards - the section Execution Of The Shards Part Of The Split Pipeline in this chapter discusses why. -
Optimisations Applied In Shards Part. For the
$sortor$groupblocking stages where the pipeline splits, the blocking stage divides into two. The runtime executes the first phase of the blocking stage as the last stage of theshardsPartof the divided pipeline. It then completes the stage's remaining work as the first stage of themergerPart. For a$sortstage, this means the cluster conducts a large portion of the sorting work in parallel on all shards, with a remaining "merge sort" occurring at the final location. For a$groupstage, the cluster performs the grouping in parallel on every shard, accumulating partial sums and totals ahead of its final merge phase. Consequently, the runtime does not have to ship masses of raw ungrouped data from the source shards to where the runtime merges the partially formed groups. -
Merger Part Running From A Single Location. The specific location where the runtime executes the pipeline's
mergerPartstages depends on several variables. The explain plan shows the location chosen by the runtime in themergeTypefield of its output. In these two examples, the locations aremongosandanyShard, respectively. This chapter's Execution Of The Merger Part Of The Split Pipeline section outlines the rules that the aggregation runtime uses to decide this location. -
Final Merge Sorting When The Sort Stage Is Split. The
$sort's final phase shown in themergerPartof the first pipeline is not a blocking operation, whereas, with$groupshown in the second pipeline,$group's final phase is blocking. This chapter's Difference In Merging Behaviour For Grouping Vs Sorting section discusses why.
Unfortunately, if you are running your aggregations in MongoDB versions 4.2 to 5.2, the explain plan generated by the aggregation runtime erroneously neglects to log the final phase of the
$sortstage in the pipeline'smergerPart. This is caused by a now fixed explain plan bug but rest assured that the final phase of the$sortstage (the "merge sort") does indeed happen in the pipeline'smergerPartin all the MongoDB versions.
Execution Of The Shards Part Of The Split Pipeline
When a mongos receives a request to execute an aggregation pipeline, it needs to determine where to target the shards part of the pipeline. It will endeavour to run this on the relevant subset of shards rather than broadcasting the work to all.
Suppose there is a $match stage occurring at the start of the pipeline. If the filter for this $match includes the shard key or a prefix of the shard key, the mongos can perform a targeted operation. It routes the shards part of the split pipeline to execute on the applicable shards only.
Furthermore, suppose the runtime establishes that the $match's filter contains an exact match on a shard key value for the source collection. In that case, the pipeline can target a single shard only, and doesn't even need to split the pipeline into two. The entire pipeline runs in one place, on the one shard where the data it needs lives. Even if the $match's filter only has a partial match on the first part of the shard key (the "prefix"), if this spans a range of documents encapsulated within a single chunk, or multiple chunks on the same shard only, the runtime will just target the single shard.
Execution Of The Merger Part Of The Split Pipeline (If Any)
The aggregation runtime applies a set of rules to determine where to execute the merger part of an aggregation pipeline for a sharded cluster and whether a split is even necessary. The following diagram captures the four different approaches the runtime will choose from.
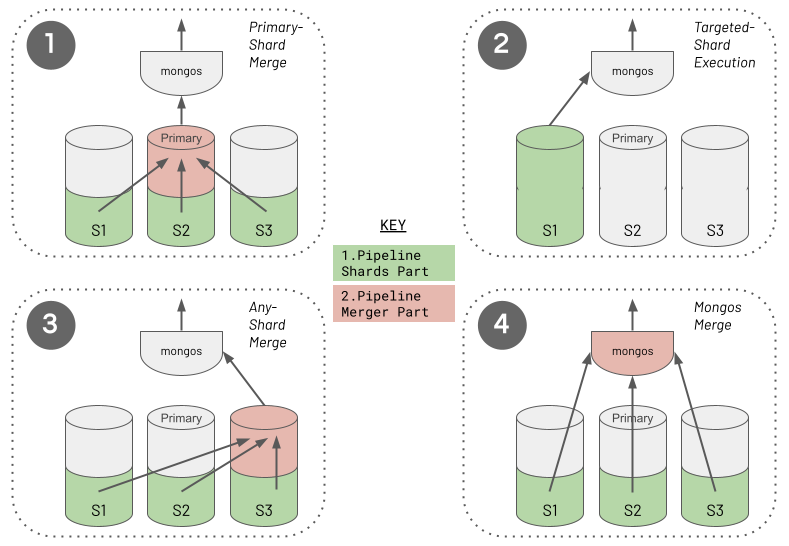
The aggregation runtime selects the merger part location (if any) by following a decision tree, with four possible outcomes. The list below outlines the ordered decisions the runtime takes. However, it is crucial to understand that this order does not reflect precedence or preference. Achieving either the Targeted-Shard Execution (2) or Mongos Merge (4) is usually the preferred outcome for optimum performance.
-
Primary-Shard Merge. When the pipeline contains a stage referencing a second unsharded collection, the aggregation runtime will place this stage in the merger part of the split pipeline. It executes this merger part on the designated primary shard, which holds the referenced unsharded collection. This is always the case for the stages that can only reference unsharded collections (i.e. for
$outgenerally or for$lookupand$graphLookupin MongoDB versions before 5.1). This is also the situation if the collection happens to be unsharded and you reference it from a$mergestage or, in MongoDB 5.1 or greater, from a$lookupor$graphLookupstage. -
Targeted-Shard Execution. As discussed earlier, if the runtime can ensure the pipeline matches the required subset of the source collection data to just one shard, it does not split the pipeline, and there is no merger part. Instead, the runtime executes the entire pipeline on the one matched shard, just like it would for non-sharded deployments. This optimisation avoids unnecessarily breaking the pipeline into two parts, where intermediate data then has to move from the shards part(s) to the merger part. The behaviour of pinning to a single shard occurs even if the pipeline contains a
$merge,$lookupor$graphLookupstage referencing a second sharded collection containing records dispersed across multiple shards. -
Any-Shard Merge. Suppose you've configured
allowDiskUse:truefor the aggregation to avoid the 100 MB memory consumption limit per stage. If one of the following two situations is also true, the aggregation runtime must run the merger part of the split pipeline on a randomly chosen shard (a.k.a. "any shard"):- The pipeline contains a grouping stage (which is where the split occurs), or
- The pipeline contains a
$sortstage (which is where the split occurs), and a subsequent blocking stage (a grouping or$sortstage) occurs later.
For these cases, the runtime picks a shard to execute the merger, rather than merging on the mongos, to maximise the likelihood that the host machine has enough storage space to spill to disk. Invariably, each shard's host machine will have greater storage capacity than the host machine of a mongos. Consequently, the runtime must take this caution because, with
allowDiskUse:true, you are indicating the likelihood that your pipeline will cause memory capacity pressure. Notably, the aggregation runtime does not need to mitigate the same risk by merging on a shard for the other type of blocking stage (a$sort) when$sortis the only blocking stage in the pipeline. You can read why a single$sortstage can be treated differently and does not need the same host storage capacity for merging in this chapter's Difference In Merging Behaviour For Grouping Vs Sorting section. -
Mongos Merge. This is the default approach and location. The aggregation runtime will perform the merger part of the split pipeline on the mongos that instigated the aggregation in all the remaining situations. If the pipeline's merger part only contains streaming stages (described in the chapter Pipeline Performance Considerations), the runtime assumes it is safe for the mongos to run the remaining pipeline. A mongos has no concept of local storage to hold data. However, it doesn't matter in this situation because the runtime won't need to write to disk as RAM pressure will be minimal. The category of streaming tasks that supports a Mongos Merge also includes the final phase of a split
$sortstage, which processes data in a streaming fashion without needing to block to see all the data together. Additionally, suppose you have definedallowDiskUse:false(the default). In that case, you are signalling that even if the pipeline has a$groupstage (or a$sortstage followed by another blocking stage), these blocking activities will not need to overspill to disk. Performing the final merge on the mongos is the default because fewer network data transfer hops are required to fulfil the aggregation, thus reducing latency compared with merging on "any shard".
Regardless of where the merger part runs, the mongos is always responsible for streaming the aggregation's final batches of results back to the client application.
It is worth considering when no blocking stages exist in a pipeline. In this case, the runtime executes the entire pipeline in parallel on the relevant shards and the runtime streams each shard's output directly to the mongos. You can regard this as just another variation of the default behaviour (4 - Mongos Merge). All the stages in the aggregation constitute just the shards part of the pipeline, and the mongos "stream merges" the final data through to the client.
Difference In Merging Behaviour For Grouping Vs Sorting
You will have read in the Pipeline Performance Considerations chapter about $sort and $group stages being blocking stages and potentially consuming copious RAM. Consequently, you may be confused by the statement that, unlike a $group stage, when the pipeline splits, the aggregation runtime will finalise a $sort stage on a mongos even if you specify allowDiskUse:true. This is because the final phase of a split $sort stage is not a blocking activity, whereas the final phase of a split $group stage is. For $group, the pipeline's merger part must wait for all the data coming out of all the targeted shards. For $sort, the runtime executes a streaming merge sort operation, only waiting for the next batch of records coming out of each shard. As long as it can see the first of the sorted documents in the next batch from every shard, it knows which documents it can immediately process and stream on to the rest of the pipeline. It doesn't have to block waiting to see all of the records to guarantee correct ordering.
This optimisation doesn't mean that MongoDB has magically found a way to avoid a $sort stage being a blocking stage in a sharded cluster. It hasn't. The first phase of the $sort stage, run on each shard in parallel, is still blocking, waiting to see all the matched input data for that shard. However, the final phase of the same $sort stage, executed at the merge location, does not need to block.
Summarising Sharded Pipeline Execution Approaches
In summary, the aggregation runtime seeks to execute a pipeline on the subset of shards containing the required data only. If the runtime must split the pipeline to perform grouping or sorting, it completes the final merge work on a mongos, when possible. Merging on a mongos helps to reduce the number of required network hops and the execution time.
Performance Tips For Sharded Aggregations
All the recommended aggregation optimisations outlined in the Pipeline Performance Considerations chapter equally apply to a sharded cluster. In fact, in most cases, these same recommendations, repeated below, become even more critical when executing aggregations on sharded clusters:
-
Sorting - Use Index Sort. When the runtime has to split on a
$sortstage, the shards part of the split pipeline running on each shard in parallel will avoid an expensive in-memory sort operation. -
Sorting - Use Limit With Sort. The runtime has to transfer fewer intermediate records over the network, from each shard performing the shards part of a split pipeline to the location that executes the pipeline's merger part.
-
Sorting - Reduce Records To Sort. If you cannot adopt point 1 or 2, moving a
$sortstage to as late as possible in a pipeline will typically benefit performance in a sharded cluster. Wherever the$sortstage appears in a pipeline, the aggregation runtime will split the pipeline at this point (unless preceded by a$groupstage which would cause the split earlier). By promoting other activities to occur in the pipeline first, the hope is these reduce the number of records entering the blocking$sortstage. This sorting operation, executing in parallel at the end of shards part of the split pipeline, will exhibit less memory pressure. The runtime will also stream fewer records over the network to the split pipeline's merger part location. -
Grouping - Avoid Unnecessary Grouping. Using array operators where possible instead of
$unwindand$groupstages will mean that the runtime does not need to split the pipeline due to an unnecessarily introduced$groupstage. Consequently, the aggregation can efficiently process and stream data directly to the mongos rather than flowing through an intermediary shard first. -
Grouping - Group Summary Data Only. The runtime has to move fewer computed records over the network from each shard performing the shards part of a split pipeline to the merger part's location.
-
Encourage Match Filters To Appear Early In The Pipeline. By filtering out a large subset of records on each shard when performing the shards part of the split pipeline, the runtime needs to stream fewer records to the merger part location.
Specifically for sharded clusters, there are two further performance optimisations you should aspire to achieve:
-
Look For Opportunities To Target Aggregations To One Shard Only. If possible, include a
$matchstage with a filter on a shard key value (or shard key prefix value). -
Look For Opportunities For A Split Pipeline To Merge On A Mongos. If the pipeline has a
$groupstage (or a$sortstage followed by a$group/$sortstage) which causes the pipeline to divide, avoid specifyingallowDiskUse:trueif possible. This reduces the amount of intermediate data transferred over the network, thus reducing latency.